
Table of content
- Feature Engineering
- Pre-Procesing
- Correlation Analysis
- Feature Selection
- Normalization
- One-Hot Encoding
- Binning
- Regularization
- Non-Adequate Features
- Imputation Techniques
- Example
- Conclusion
Feature Engineering
When we talk about machine learning, we often talk about the algorithms and models. But the most important part of machine learning is the data itself. The quality of the data is the most important factor in determining the quality of the model. The data should be clean, relevant, and should have the right features.
The process of selecting the right features and transforming the data into a format that is suitable for the model is called feature engineering.
Pre-Procesing
The first step in feature engineering is pre-processing. This involves cleaning the data, handling missing values, and encoding categorical variables.
- Change all characters to lower-case
- Use a list of English stop words as a reference and remove them e.g. the, is ’!’ etc
- Use tokenization to convert sentence into words
- Use stemming to convert words to their root form
- Use lemmatization to convert words to their root form
- Use TF-IDF to convert words to numbers
Correlation Analysis
Correlation analysis is used to identify the relationship between the features. It is important to remove features that are highly correlated as they can cause overfitting. For example: Height and Weight are correlated when it comes to your physique — as height increases, the weight tends to increase too. If we observe an individual who is unusually tall, we can also conclude that his weight is also above the average.
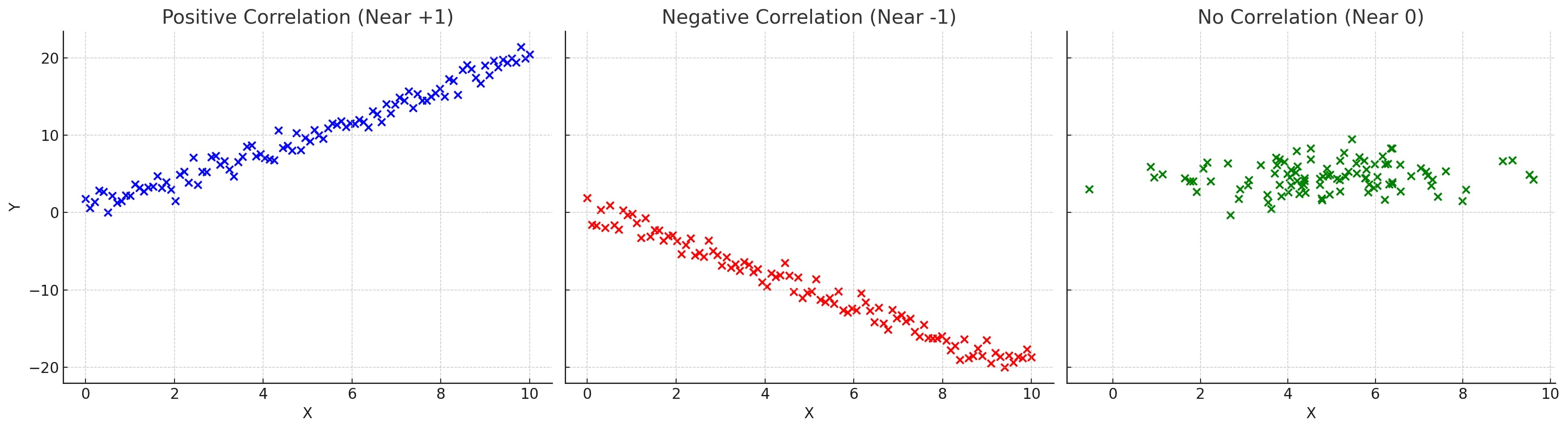
Correlation Coefficient
The correlation coefficient is a statistical measure that calculates the strength of the relationship between the relative movements of two variables. The values range between -1.0 and 1.0. A value of 1.0 indicates a perfect positive relationship, while -1.0 indicates a perfect negative relationship. A value of 0.0 indicates no relationship.
Feature Selection
Feature selection is the process of selecting the most important features from the dataset. This is done to reduce the dimensionality of the dataset and to improve the performance of the model. There are several techniques for feature selection:
- Filter Methods: These methods use statistical measures to select the most important features. Examples include correlation analysis and chi-square test.
- Wrapper Methods: These methods use the model to evaluate the importance of the features. Examples include forward selection and backward elimination.
- Embedded Methods: These methods use the model to select the most important features. Examples include LASSO and Ridge regression.
- Feature Importance: This is a technique that uses the model to evaluate the importance of the features. The importance of the features is calculated using the featureimportances attribute of the model.
- Principal Component Analysis (PCA): This is a technique that reduces the dimensionality of the dataset by transforming the features into a new set of features that are uncorrelated.
- t-Distributed Stochastic Neighbor Embedding - t-SNE is a technique that reduces the dimensionality of the dataset by transforming the features into a new set of features that are uncorrelated.
- Independent Component Analysis: This is a technique that reduces the dimensionality of the dataset by transforming the features into a new set of features that are statistically independent.
Normalization
Normalization is the process of scaling the features so that they have a mean of 0 and a standard deviation of 1. This is done to ensure that the features are on the same scale and to improve the performance of the model.
Normalization of numeric variables can help the learning process if there are very large range differences between numeric variables because variables with the highest magnitude could dominate the ML model, whether the feature is informative regarding the target or not. - Example: Consider a dataset with a feature called age that ranges between 18-35 and a product price that ranges between $50 – $5,000. Since the product price has a significantly larger value than the age, the model will treat the product price with “more importance”. This would have a negative impact on the model’s ability to classify data correctly. - That means the model will produce low precision and low accuracy scores.
Standardization is used to center the data by removing the mean (mean becomes 0) and scaling to unit variance (standard deviation becomes 1). This is done to ensure that the features are on the same scale and to improve the performance of the model.
One-Hot Encoding
For categorical values
| weather | … | |
|---|---|---|
| 0 | sunny | … |
| 1 | cloudy | … |
| 2 | cloudy | … |
| 3 | sunny | … |
converted to
| is_sunny | is_cloudy | … | |
|---|---|---|---|
| 0 | 1 | 0 | … |
| 1 | 0 | 1 | … |
| 2 | 0 | 1 | … |
| 3 | 1 | 0 | … |
- The OneHotEncoder transformer has the following methodologies you can use to drop one of the categories per feature:
None,first,array. None is the default methodology.
- One Hot Encoding is not useful where there are many features in a dataset. As it will make dataset really wide (no of columns)
- It helps convert categorical variables into a form that could be provided to ML algorithms to do a better job in prediction.
Binning
Binning is the process of converting continuous variables into categorical variables. This is done to reduce the complexity of the model and to improve the performance of the model.
Types of Binning
- Categorical Binning: The categorical binning processor takes two inputs, a numerical variable and a parameter called bin number, and outputs a categorical variable. The purpose is to discover non-linearity in the variable’s distribution by grouping observed values together.
- Numerical Binning: The numerical binning processor takes two inputs, a numerical variable and a parameter called bin number, and outputs a numerical variable. The purpose is to discover non-linearity in the variable’s distribution by grouping observed values together.
- Quantile Binning: The quantile binning processor takes two inputs, a numerical variable and a parameter called bin number, and outputs a categorical variable. The purpose is to discover non-linearity in the variable’s distribution by grouping observed values together.” Because Quantile binning is used to create uniform bins of classifications, it would be the right choice to give you uniform age classifications that are limited in number. For example, you could create classification bins such as: Under 30, 30 to 50, Over 50. Or even better: Millennial, Generation X, Baby Boomer, etc.
Regularization
Regularization is the process of adding a penalty term to the loss function to prevent overfitting. There are two types of regularization:
L1 (Lasso) Regularization
This is also known as Lasso regularization. It adds the absolute value of the coefficients to the loss function. This results in sparse coefficients, which means that some coefficients are set to zero.
L2 (Ridge) Regularization
This is also known as Ridge regularization. It adds the square of the coefficients to the loss function. This results in small coefficients, which means that the coefficients are close to zero.
| L1 | L2 | |
|---|---|---|
| Features | If goal is to use few features | If you want to consider all features |
| Purpose | Dimensionality Reduction | |
| Efficiency | Computationally efficient | |
| When | If feature has outliers, Overfitting | Overfitting |
Non-Adequate Features
- Non-Informative Features: Features that do not provide any information to the model. These features should be removed from the dataset.
- Redundant Features: Features that are highly correlated with other features. These features should be removed from the dataset.
- Irrelevant Features: Features that are not relevant to the model. These features should be removed from the dataset.
- Noisy Features: Features that contain noise. These features should be removed from the dataset.
- Inconsistent Features: Features that are inconsistent with other features. These features should be removed from the dataset.
- Non-Linear Features: Features that are non-linear with the target variable. These features should be removed from the dataset.
- Non-Stationary Features: Features that are non-stationary with the target variable. These features should be removed from the dataset.
- Non-Linearly Separable Features: Features that are non-linearly separable with the target variable. These features should be removed from the dataset.
- Non-Linearly Independent Features: Features that are non-linearly independent with the target variable. These features should be removed from the dataset.
- Non-Linearly Dependent Features: Features that are non-linearly dependent with the target variable. These features should be removed from the dataset.
Imputation Techniques
Imputation is the process of replacing missing values with a value. There are several techniques for imputation:
- Mean Imputation: This is the process of replacing missing values with the mean of the feature.
- Most Frequent Imputation: This is the process of replacing missing values with the most frequent value of the feature.
- K-Nearest Neighbors Imputation: This is the process of replacing missing values with the value of the nearest neighbor.
- Linear Regression Imputation: This is the process of replacing missing values with the value predicted by a linear regression model.
- Decision Tree Imputation: This is the process of replacing missing values with the value predicted by a decision tree model.
- Random Forest Imputation: This is the process of replacing missing values with the value predicted by a random forest model.
- Multiple Imputation: This is the process of replacing missing values with multiple values and then averaging the results.
- Deep Learning Imputation: This is the process of replacing missing categorical values with the value predicted by a deep learning model.
- Multivariate Imputation by Chained Equations (MICE): This is the process of replacing missing values with the value predicted by a regression model.
Example
Sample Data
price,area,bedrooms,bathrooms,stories,mainroad,guestroom,basement,hotwaterheating,airconditioning,parking,prefarea,furnishingstatus
13300000,7420,4,2,3,yes,no,no,no,yes,2,yes,furnished
12250000,8960,4,4,4,yes,no,no,no,yes,3,no,furnished
12250000,9960,3,2,2,yes,no,yes,no,no,2,yes,semi-furnished
12215000,7500,4,2,2,yes,no,yes,no,yes,3,yes,furnished
11410000,7420,4,1,2,yes,yes,yes,no,yes,2,no,furnished
10850000,7500,3,3,1,yes,no,yes,no,yes,2,yes,semi-furnished
10150000,8580,4,3,4,yes,no,no,no,yes,2,yes,semi-furnished
10150000,16200,5,3,2,yes,no,no,no,no,0,no,unfurnished
9870000,8100,4,1,2,yes,yes,yes,no,yes,2,yes,furnished
9800000,5750,3,2,4,yes,yes,no,no,yes,1,yes,unfurnished
9800000,13200,3,1,2,yes,no,yes,no,yes,2,yes,furnishedObservations:
- Target variable: price
- Imputation Techniques: Not needed as there are no missing values. I want to keep code clean therefore not adding this step. However you can check using this code
has_missing_values = data.isnull().values.any() print("Are there any missing values? ", has_missing_values) # or missing_values = data.isnull().sum() - Feature Engineering: Convert categorical columns to numeric using one-hot encoding
Training
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.preprocessing import OneHotEncoder
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
data = pd.read_csv('housing.csv')
# Feature Engg: Convert categorical columns to numeric using one-hot encoding
categorical_features = ['mainroad', 'guestroom', 'basement', 'hotwaterheating', 'airconditioning', 'prefarea', 'furnishingstatus']
numeric_features = ['area', 'bedrooms', 'bathrooms', 'stories', 'parking']
preprocessor = ColumnTransformer(transformers=[ # ColumnTransformer allows to define Numerical and Categorical values in a single step.
('num', 'passthrough', numeric_features),
('cat', OneHotEncoder(), categorical_features)
])
model = Pipeline(steps=[('preprocessor', preprocessor), ('regressor', LinearRegression())]) # Define the model
# Split data into training and testing sets
X = data.drop('price', axis=1)
y = data['price']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)
model.fit(X_train, y_train) # Fit the model - training the modelPrediction
import pandas as pd
new_data = pd.DataFrame({
'area': [1000],
'bedrooms': [2],
'bathrooms': [4],
'stories': [3],
'mainroad': ['yes'],
'guestroom': ['no'],
'basement': ['yes'],
'hotwaterheating': ['no'],
'airconditioning': ['yes'],
'parking': [2],
'prefarea': ['no'],
'furnishingstatus': ['semi-furnished']
})
predicted_price = model.predict(new_data)
formatted_price = f"{predicted_price[0]:,.0f}"
print(f"The predicted price of the house is: ${formatted_price}")
# The predicted price of the house is: $7,799,589Conclusion
Feature engineering is the most important part of machine learning. However, it is often overlooked. It is important to spend time on feature engineering to ensure that the data is clean, relevant, and has the right features. This will help to improve the performance of the model and to make better predictions.